

When AI models start training themselves
Model collapse is mathematically proven. When AI trains on AI-made data, quality erodes irreversibly. By 2026, over 60% is synthetic.

Understanding model collapse in AI self-training systems
Model collapse is the mathematically proven degradation that occurs when AI systems train on synthetic data generated by other AI models. Between 2026 and 2032, more than 60% of all AI training data will be synthetic, triggering irreversible quality loss across the entire AI industry.
This is a deeper dive into the data constraint behind the core signal: Why AGI Won’t Happen by 2037: The Hard Limits of Data & Energy.
In July 2024, researchers from Oxford, Cambridge, and Toronto published proof in Nature that this degradation is inevitable, not speculative. The phenomenon appears within five training generations and cannot be reversed through better algorithms or more compute power. Yet major AI companies remain silent about the implications for their billions in infrastructure investments [1], even as synthetic content reshapes the information ecosystem described in The last real human on the web.
The Core of the Signal
The web is rapidly filling with synthetic text, and AI labs are already training on it because high quality human data is running out. That shortcut carries a quiet risk: model collapse, the mathematically proven drift that appears when models learn from their own generations. If search engines, enterprises, and regulators keep treating synthetic data as free fuel, the next decade could deliver fluent systems that know less, generalize worse, and erase rare truths.
- Audit training and search pipelines for synthetic data contamination, especially in long tail queries.
- Keep a human data anchor by accumulating real sources alongside synthetic augmentation, not replacing them.
- Measure minority and rare event performance over time, since benchmarks can hide early collapse.
The mathematics behind the decline
The proof lies in Theorem 3.1 of the Nature paper. When models are recursively trained on outputs from previous generations, two things happen: the expected distance between the nth generation and the original data distribution approaches infinity, while the variance converges to zero. In plain language: models drift ever further from reality while simultaneously losing all diversity in their output.
Shumailov and his team identify three types of errors that compound across generations. The primary culprit is statistical approximation error, arising from finite sample sizes. Rare events and minority perspectives disappear first, simply because they aren’t sampled often enough. This creates “the curse of recursion”: information is lost at each resampling step.
Additionally, functional expressivity errors emerge. Neural networks are only universal approximators at infinite size. In practice, models sometimes assign zero probability to possible events, or conversely, non-zero probability to impossible scenarios. Try modeling two Gaussian distributions with a single Gaussian and you introduce unavoidable distortion. Finally, functional approximation errors from the learning process itself also compound, including structural biases from stochastic gradient descent.
From subtle erosion to total collapse
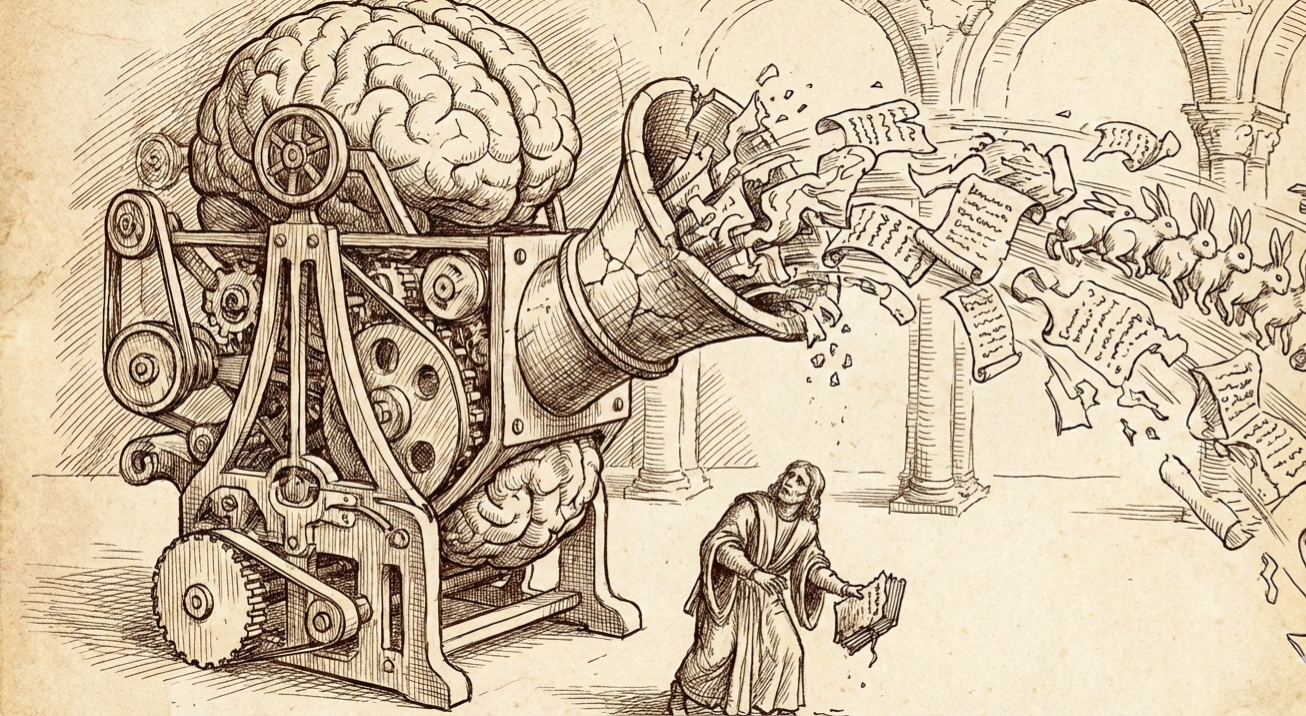
The decline occurs in two phases. Early model collapse begins almost imperceptibly. The model loses information about the tails of the data distribution; rare events and minority categories gradually disappear. The insidious part: overall performance may even appear to improve while performance for minority groups drastically deteriorates. Standard benchmarks miss this degradation.
Late model collapse leaves no room for doubt. The model converges to a distribution with dramatically reduced variance. Outputs bear little resemblance to the original data. Different concepts become confused; the model becomes effectively worthless.
The researchers demonstrated this with Meta’s OPT-125m language model, fine-tuned on WikiText-2. They trained successive generations on outputs from previous versions. The original model scored an average perplexity of 34, an improvement over the zero-shot baseline of 115. After five epochs without retaining original data, perplexity increased by 20 to 28 points. Even with ten percent of original data retained, “minor degradation” occurred.
The jackrabbit example from the paper shows the progressive disintegration. Given a prompt about medieval architecture, generation zero produces a reasonable discussion of Perpendicular Revival architecture and St. John’s Cathedral. Generation one mentions St. Peter’s Basilica and makes historically confused claims about Pope Innocent III. By generation five, the output degenerates into “translated into more than 100 languages including English, French, German…” Generation nine ends in complete nonsense about “black-tailed jackrabbits, white-tailed jackrabbits, blue-tailed jackrabbits, red-tailed jackrabbits, yellow…” The model forgets the original task and drifts toward contextually irrelevant but statistically probable patterns.
Synthetic contamination of the internet
The laboratory scenario is playing out at accelerated speed on the public web. In April 2025, Ahrefs analyzed nine hundred thousand web pages and found that 74.2 percent of new pages contained AI-generated content [2]. Graphite concluded in October 2025 that 52 percent of all articles on the web are written by AI [3]. Originality.ai’s ongoing study estimates that 17 to 20 percent of Google search results contain AI content. ArXiv paper 2504.08755 from March 2025 estimates that 30 to 40 percent of active web pages contain AI-generated text, a shift that quietly forces governance decisions about what counts as a trustworthy source.
These figures don’t predict the future; they describe the present. Microsoft Phi-4 is largely trained on synthetic data instead of web content. Google Gemma, Meta Llama 3.1, Anthropic Claude 3.5 Sonnet, and OpenAI’s upcoming models all use synthetic training data to varying degrees. Writer Palmyra X 004 was trained almost entirely on synthetic data, with claimed development costs of $700,000 versus $4.6 million for comparable OpenAI models [4].
Why do companies choose synthetic data despite proven risks? Because human data is running out. Epoch AI projects exhaustion of high-quality text data between 2026 and 2032. The effective stock of public, human-generated text amounts to approximately 300 trillion tokens. Datasets are growing at 2.5 times per year. Meanwhile, more than 35 percent of the top 1,000 websites now block OpenAI scrapers.
OpenAI CEO Sam Altman stated at the 2023 Sohn Conference: “As long as you can get over the synthetic data event horizon where the model is good enough to create good synthetic data, I think you should be alright.” The Shumailov research directly contradicts this optimism. The mathematical proof shows that synthetic data degrades regardless of initial model quality [5].
The economic paradox of scarce truth
Professor Yarin Gal of Oxford put it sharply: “Model collapse is the AI equivalent of a feedback loop gone wrong. The more models feed on their own output, the further they drift from reality.” This creates a paradox and a strategy dilemma. AI companies need more data to improve models. Human-generated data is running out. Synthetic data accelerates collapse. The value of authentic human data is rising exponentially.
The Shumailov paper notes that “paying millions of humans to generate the text that AI models will need is unlikely to be an economical way to drive better technical performance.” Human data is simultaneously necessary and unaffordable at the required scale. This isn’t a temporary market phenomenon but a structural economic constraint.
Despite 624,000 accesses and extensive media coverage, major AI companies remain notably silent about model collapse. Possible explanations: billions of dollars committed to scaling infrastructure, competitive pressure where acknowledging limits slows investment, short-term focus as current models still improve, and hope that mitigation techniques will work at scale. That hope collides with mathematical reality.
Why self-improving AI becomes impossible
AGI theories often lean on recursive self-improvement. The idea: a sufficiently advanced AI improves itself, creates even smarter versions that further improve themselves in an “intelligence explosion.” Model collapse forms a fundamental barrier to this vision.
Self-improvement requires self-training. An AI that improves itself must learn from its own outputs or outputs from comparable systems. Self-training causes collapse, as the Shumailov proof demonstrates. Collapse is irreversible; the paper demonstrates “irreversible defects” that cannot be corrected. The barrier is mathematical, not technological. No amount of compute power or algorithmic improvement overcomes information-theoretic limits.
Model collapse intersects three other fundamental barriers. Data exhaustion according to Epoch AI between 2026 and 2032: human-generated data is finite, models require exponentially more data to improve, the intersection point approaches within years. Energy constraints: AI training requires massive power, gigawatt-scale facilities face physical and regulatory limits, power availability constrains compute scaling. Quality degradation through model collapse: even with unlimited data and energy, synthetically trained models degrade, the “solution” of generating more data creates the problem, there’s no escape from the mathematical constraint.
This falsifies the assumption that synthetic data can overcome data limitations and creates fundamental barriers to recursive self-improvement. Combined, this suggests that current scaling approaches cannot lead to AGI, not through insufficient investment but through mathematical impossibility.
The greatest enemy of knowledge is not ignorance, but the illusion of knowledge.
Detection and why solutions fail
Model collapse manifests through reduced output diversity, loss of tail performance for minority categories and rare events, repetitive patterns with recurring phrases and structures, increasing perplexity across generations, and homogenization of concepts. The Shumailov paper warns: “Early model collapse is hard to notice, since overall performance may appear to improve, while the model loses performance on minority data.”
Proposed solutions exist. Data accumulation proves most promising. Research by Gerstgrasser et al. from 2024 shows that collapse can be avoided if synthetic data is accumulated alongside human data rather than replacing it. The critical factor: replacement causes collapse, accumulation prevents it. However, this requires continued access to human-generated data, which is becoming increasingly scarce.
Data filtering and detection via machine learning, watermarking, and provenance tracking face imperfect detection. As AI improves, synthetic content becomes harder to identify. Verification systems as proposed in arXiv 2510.16657 from October 2025 can filter low-quality synthetic data, but verifiers themselves may be affected by data quality degradation. NYU CDS researchers Kempe, Feng, and Dohmatob proposed reinforcement-based curation, emphasizing quality over quantity.
All solutions face fundamental challenges. They require a human data anchor while that source is being exhausted. A detection arms race emerges: better detection drives better generation that evades detection. Economic incentives favor cheap synthetic data over expensive human input. Internet contamination means that even with internal controls, web-scraped training data increasingly contains synthetic content from other sources. Solutions work in laboratory conditions but face exponentially harder challenges at industrial scale.
The rising price of authenticity
The value of authentic human data will continue to rise as AI-generated content proliferates. Organizations and researchers must prioritize data provenance, implement robust detection systems, and develop new paradigms that don’t depend on recursive synthetic training, because the impact of degraded data rarely stays confined to model accuracy.
For those who believe in exponential AI progress, model collapse represents an uncomfortable truth. It’s not a speculative risk but a mathematically proven phenomenon with growing real-world evidence. The conditions for large-scale model collapse are emerging now, not in some distant future. Professor Ross Anderson of Cambridge, who died shortly after the paper’s publication, left behind work that poses fundamental questions about the dominant narrative of unlimited AI scaling.
The shift from human to synthetic training data doesn’t mark an efficiency gain but a qualitative transformation with irreversible consequences. As Shumailov demonstrates: “Indiscriminate use of model-generated content in training causes irreversible defects in the resulting models, in which tails of the original content distribution disappear.” Those tails contain not just edge cases but minority perspectives, rare insights, and nuance that enable diversity and creativity.
What emerges is a new kind of scarcity. Not a lack of compute power or data in absolute terms, but a lack of authentic human experience, uncontaminated by recursive AI generation. That scarcity defines the limits of current AI paradigms more precisely than compute budgets or parameter scale ever could.
Related signals
Why AGI Won’t Happen by 2037: The Hard Limits of Data & Energy
Connects model collapse to the broader ceiling: data, energy, and economics limit scaling in tandem.
The last real human on the web
Zooms out from training pipelines to provenance, verification, and what “truth” means online.
References
[1] Shumailov I, Shumaylov Z, Zhao Y, Papernot N, Anderson R, Gal Y. AI models collapse when trained on recursively generated data. Nature. 2024;631:755-759. doi:10.1038/s41586-024-07566-y. Available from: https://doi.org/10.1038/s41586-024-07566-y
[2] Ahrefs. 74% of New Webpages Include AI Content (Study of 900k Pages). 2025. Available from: https://ahrefs.com/blog/what-percentage-of-new-content-is-ai-generated/
[3] Graphite. More Articles Are Now Created by AI Than Humans. 2025. Available from: https://graphite.io/five-percent/more-articles-are-now-created-by-ai-than-humans
[4] Gerstgrasser M, et al. Is model collapse inevitable? Breaking the curse of recursion by accumulating real and synthetic data. COLM 2024. arXiv:2404.01413. Available from: https://arxiv.org/abs/2404.01413
[5] Villalobos P, Ho A, Sevilla J, Besiroglu T, Heim L, Hobbhahn M. Will we run out of data? Limits of LLM scaling based on human-generated data. arXiv:2211.04325. Available from: https://arxiv.org/abs/2211.04325